Unsupervised feature selection method based on iterative similarity graph factorization and clustering by modularity
Jan 1, 2022·,,·
0 min read
Marcos De S. Oliveira
Sergio R. De M. Queiroz
Francisco De A. T. De Carvalho
Abstract
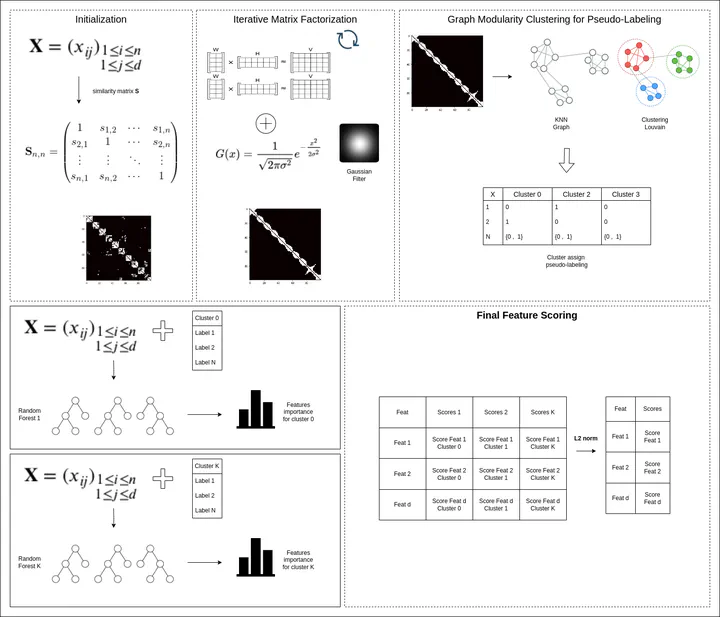
Feature selection is an important research area aimed at eliminating unwanted features from high-dimensional datasets. Feature selection methods are categorized according to the availability of labels. Supervised methods usually select features that have high correlations with the data labels, however, this cannot be done by unsupervised methods, since the labels are not available, making the development of them even more challenging. Some unsupervised methods proposed in the literature get around this problem by generating “pseudo-labels”, using clustering techniques, and then making feature selection as in the supervised scenario. There are also methods in which the selection is not guided by a clustering criterion, generally performing some kind of reconstruction of the original dataset in low dimensionality. However, in both approaches a local structure is generated, usually starting from a similarity graph built by using the entire set of features. This may compromise the results of the methods when there are many irrelevant and noisy features, which makes it difficult to reveal patterns or an initial representation of the data. Another drawback of some current methods is the large amount of hyper-parameters, or the computational time required for a single execution, which can render such methods unfeasible for some large datasets. In order to address these problems, it is proposed in this work a new unsupervised feature selection method, called KNMFS, which performs the scoring of the features in low computational time using a three-step procedure: (1) a similarity graph learning step based on non-negative iterative matrix factorization together with a Gaussian filter to mitigate the noise effects caused by irrelevant features; (2) a clustering step from the learned graph using a modularity optimization strategy and (3) a random forest algorithm is applied to compute the scores based on the labels generated by the clustering step. To verify the effectiveness of the proposed method, experiments in real and synthetic datasets were conducted. In both cases, the obtained results showed that the KNMFS method, compared to other state-of-the-art methods, obtained good results according to the metrics of Accuracy, ARI and NMI. Friedman’s statistical tests were also performed to give stronger evidence to the reported results.
Type
Publication
Expert Systems with Applications